This is the first part in an on-going blog series about building an event sourcing system in Ruby using AWS Serverless technologies.
The Idea of a Shopping Cart
The idea of a Shopping Cart gives us a nice foundation for building an event sourced system. It is a familiar concept and introduces a type of temporal model, which helps solves problems with our data changing over time.
For example, when shoppers come to your site to purchase merchandise, you may want to know when they Add an Item to an Open Cart (a change) so related items can be suggested to them. Or perhaps, if a cart is still Open after two weeks, an email is sent to them reminding them of the items they have in their Open Cart.
For this project, we will build a small Shopping Cart application to explore event sourcing. It will have three primary requirements: opening a new cart, adding items to an existing cart, and closing an existing cart.
How Event Sourcing Works
Event sourcing is a persistence pattern that, instead of storing aggregates as whole objects in a database and making updates against them, stores them as a series of events. The first event is the event that starts the aggregate and every subsequent event is a change the aggregate has gone through.
On the other hand, to retrieve an aggregate from the database, it does not retrieve a whole object but rather all related events to the aggregate. Once these events have been retrieved, the aggregate is rehydrated (rebuilt) by iterating over each event, building up to the most recent state.
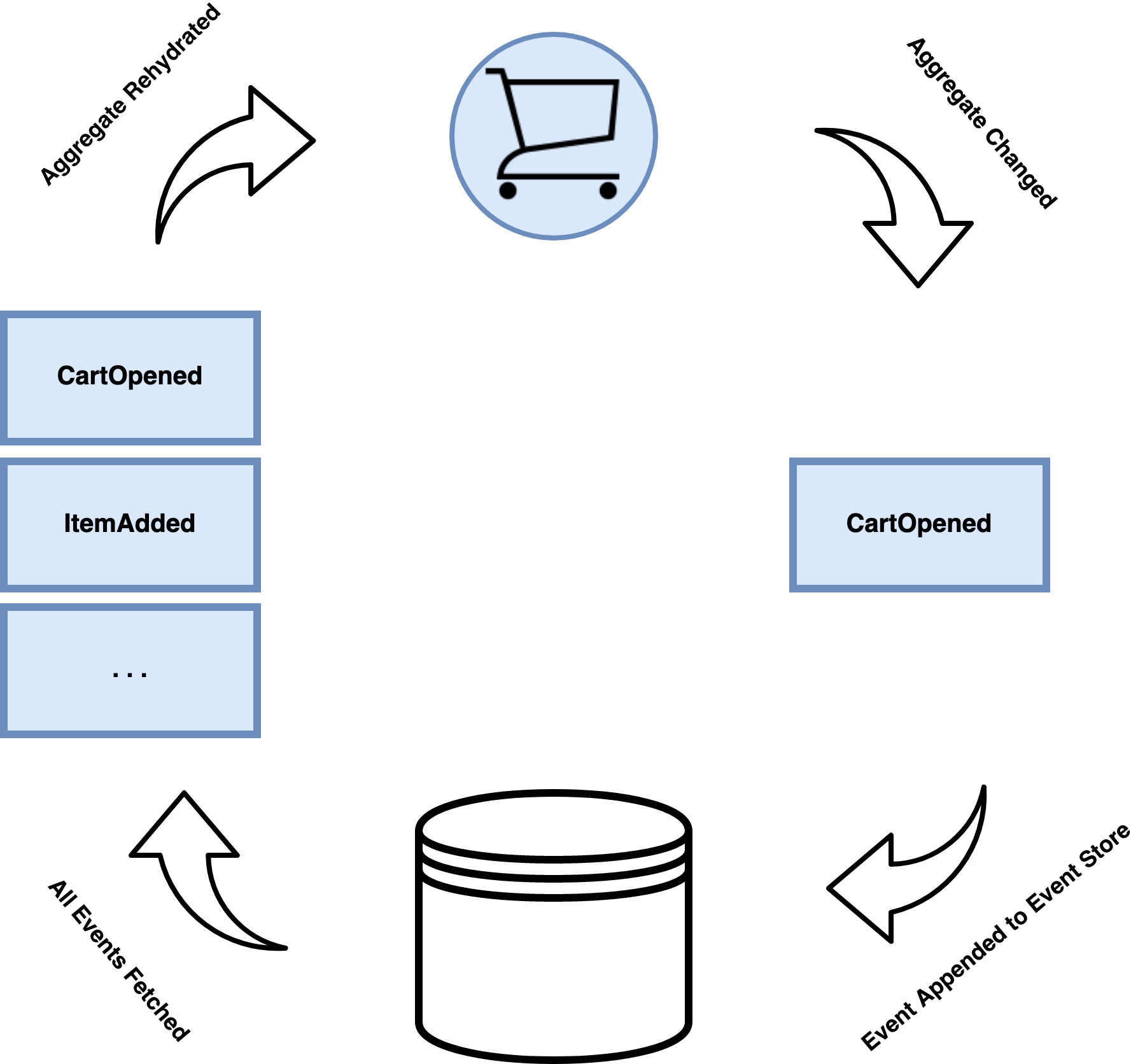
This is very similar to reducing an array of structures into a final structure. Take this array of hashes for example:
1aggregate = {name: "CatMeme"}
2=> {:name=>"CatMeme"}
3
4events = [{status: "Uploaded"}, {featured: true}]
5=> [{:status=>"Uploaded"}, {:featured=>true}]
6
7events.reduce(aggregate, :merge)
8=> {:name=>"CatMeme", :status=>"Uploaded", :featured=>true}
The final state is single structure.
What Problem Does It Solve?
Event Sourcing solves the difficult problem of when a message needs to be published alongside a data change, informing interested parties about that change. This problem often arises in both distributed systems and eventually consistent systems. Consider the following:
- What should happen to your changed data if publishing the message to the message broker should fail?
- What should happen to a published message if change fails during transaction commit against the database?
The intention is to provide a solution that does not introduce a Two-Phase Commit. Even if you could introduce Two-Phase Commits, maintaining a Transaction Co-Ordinator comes with painful pitfalls and ‘gotchas!’. For example, what happens when one system in a distributed transaction is exhausted? The entire system could come to a standstill. Yuck!
How Publishing Works
As odd as it may sound, we are actually able to leverage the underlying database technology to help with publishing messages.
Many clever database designers have solved the challenges that come with building a database by introducing a sort of log of data changes which is used to guarantee data consistency and decrease latency.
Some examples in popular databases are:
- Write Ahead Log (WAL) in PostgreSQL
- Redo Log in InnoDB, used by MariaDB, MySQL
- Journaling in MongoDB
Even more clever, the designers provided programmers with the means to hook into these logs for our own needs! These are often called streams and even come first-class in some databases such as MongoDB Streams or DynamoDB Streams. However, in some cases like PostgreSQL, some additional tricks are needed to publish data changes outside of the database.
This process is known as Change Data Capture and often happens in three steps: Capture, Transform, and Publish.
Example: Change Data Capture in PostgreSQL
Change Data Capture in PostgreSQL is possible by leveraging SQL Triggers so that whenever data is changed, we have Postgres execute a function for us. The role of this function is to, well, capture changes, transform them into a universal format (e.g. JSON), and push them to consumers who are interested in these changes.
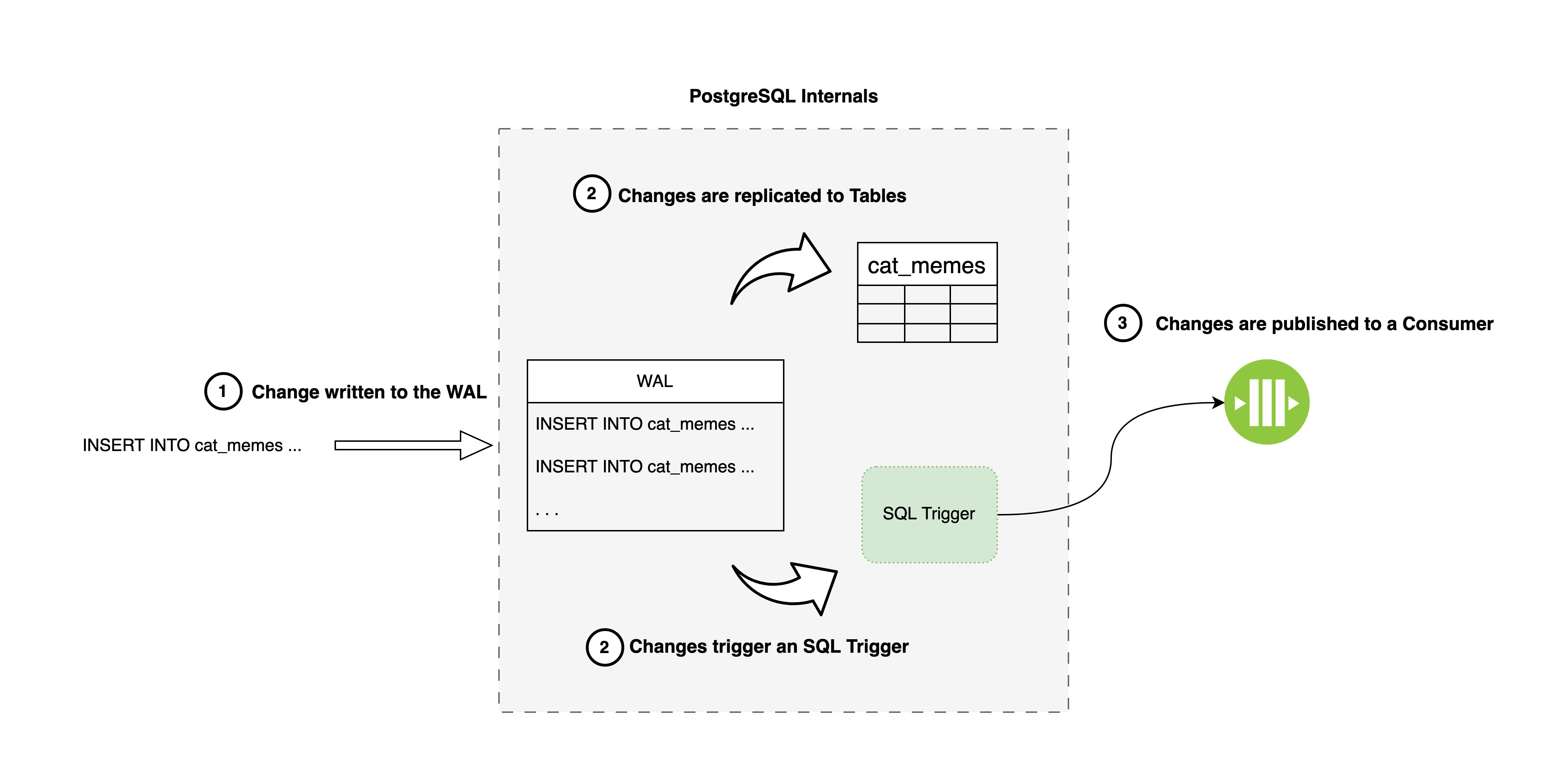
In an Event Sourcing setup, there is usually a single consumer which is the event stream. The trigger will capture newly added events to an aggregate and publish them to the stream.
Example: Change Data Capture in MongoDB
Many database designers are embracing the Change Data Capture concept and building this as a first-class feature in their databases. MongoDB is an excellent example of this.
Change Data Capture in MongoDB is facilitated by using Change Streams. Internally, changes are captured by leveraging an already built-in feature called replication, which replicates data from the Primary node to Secondary nodes.
When a change is being replicated, it’s “pushed” to a Change Stream. From there, consumers can consume these changes.
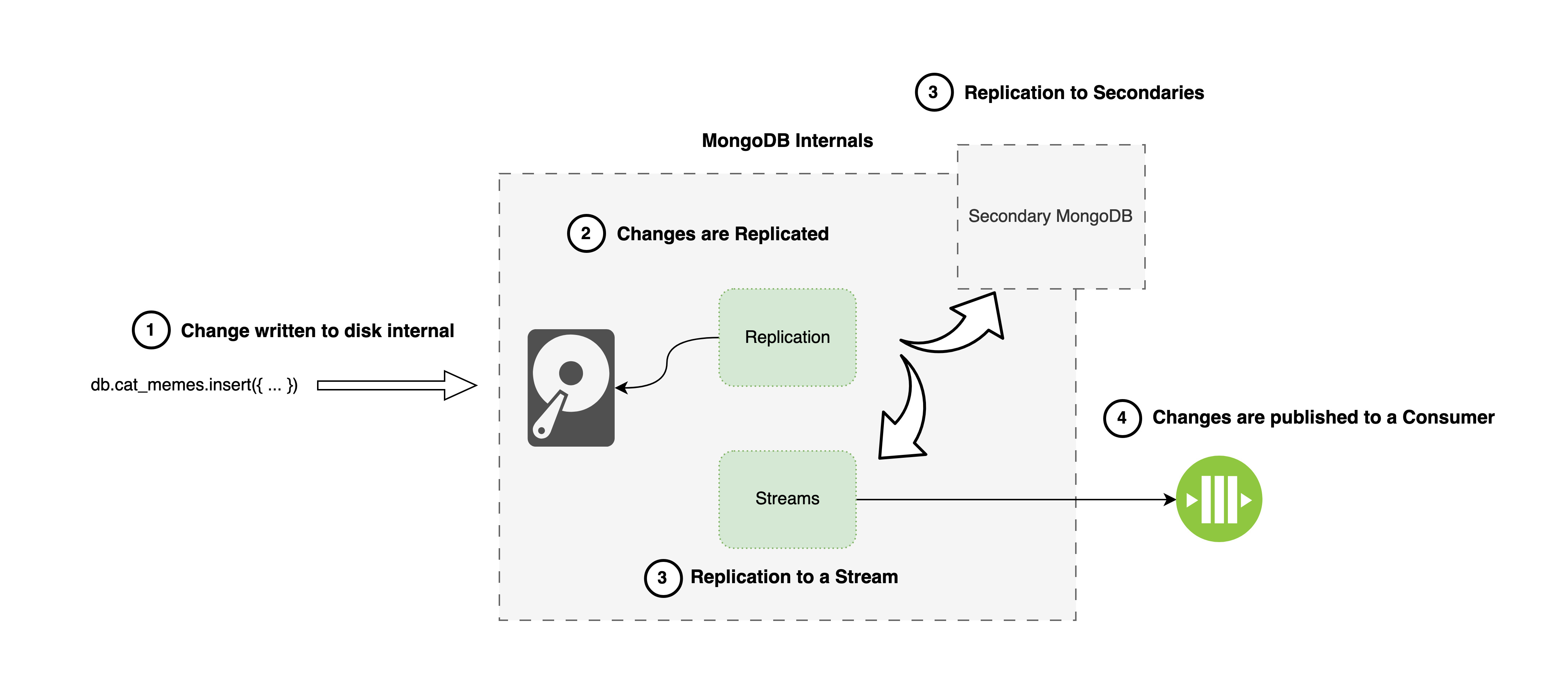
Like PostgreSQL, in an Event Sourcing setup, there is usually a single consumer, being the event stream. In the example above, the data still needs to be transformed from the format of how MongoDB publishes changes, to the format we expect from our events.
AWS Technologies and Their Roles
Our goal is to use only serverless technologies as this will help us scale on demand and be highly available. In addition, I have found that Event Sourcing is largely an infrastructure heavy pattern and comes with considerable maintenance overhead. Serverless relieves Application and DeveOps engineers of this responsibility.
Lambda
Lambda will be our computing power. It will be is used for:
- Handle our incoming client requests whether they are coming from an API, background worker, or another piece of the infrastructure.
- Provide event handlers for events published on our Event Stream.
- Transform captured events from DynamoDB and publish them to Kinesis. More on this below.
DynamoDB and DynamoDB Streams
DynamoDB will be our database. It will provide tables for our aggregates to store events and streams to publish changes.
DynamoDB is the ideal choice because it is a key-value store that allows us to store unstructured events and is highly scalable to unexpected peaks of traffic.
Kinesis Streams
A Kinesis Stream will act as our event stream. Events captured from DynamoDB tables will be published here, becoming available to our event handlers.
S3 Bucket
An S3 Bucket will be used for long term storage of our events. One of the primary characteristics of event sourcing systems is their ability to query and evaluate historical events.
Kinesis only allows data retention of up to one year, so S3 makes a great tool for long-term use. Some non-AWS streaming technologies, such as Kafka, address this by allowing log retention to be forever.
That said, we’ll also need to leverage Lambda to replay events and SQS to queue replayed events. More on this below.
SQS Queues
SQS comes in two flavours: standard queues and First-In First-Out (FIFO) queues.
The standard queue allows consumers to retrieve messages without any guarantee of ordering. This is the most common setup amongst applications, especially when dealing with high-volume. However, when your application needs to guarantee ordering, this is where FIFO queues play a valuable part.
We’ll be using FIFO to guarantee event order when event handler consume our replayed events.
CloudWatch Logs
While not part of our solution, our Lambdas will log to CloudWatch, so we can inspect any errors.
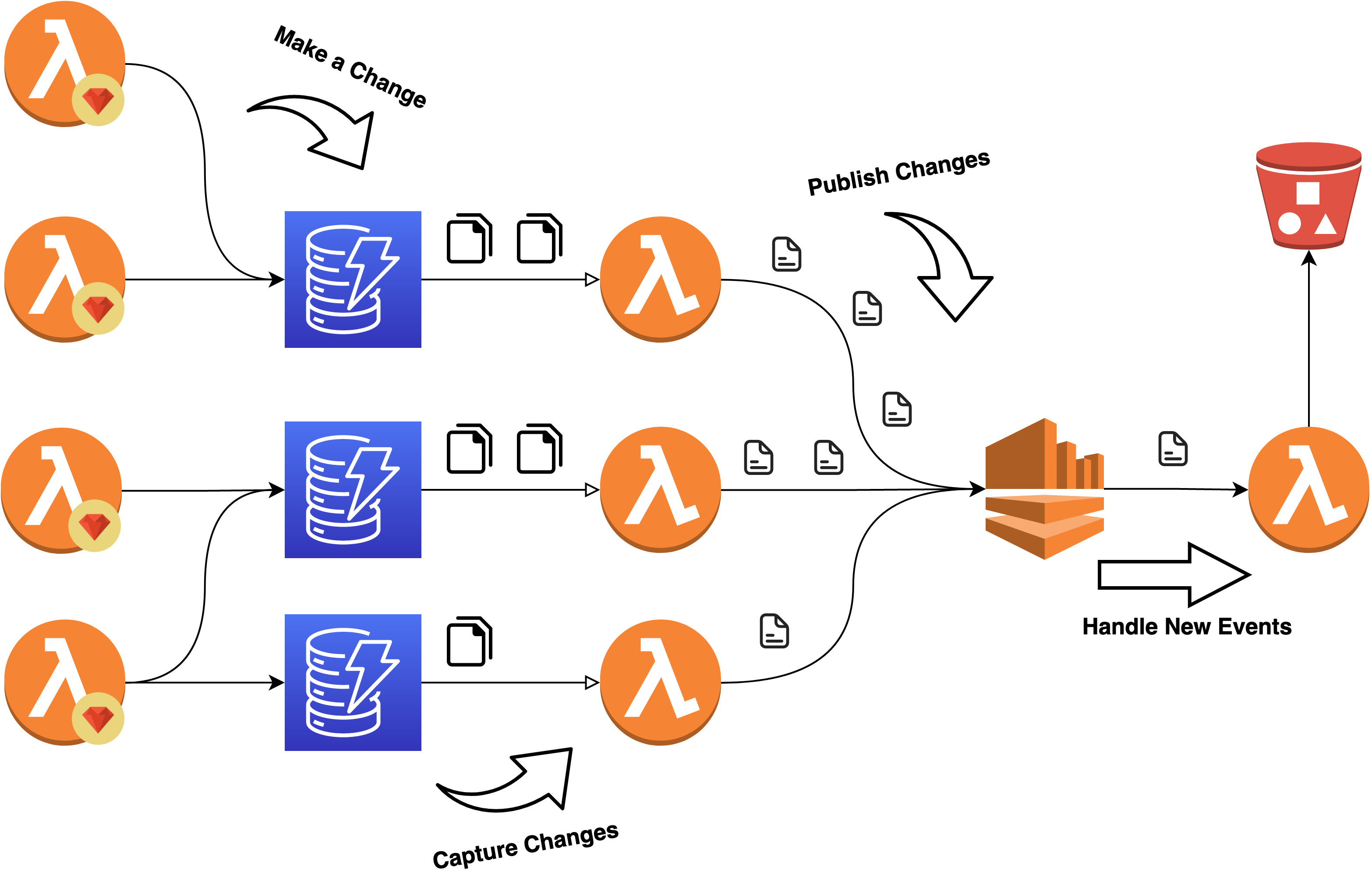
The Architecture
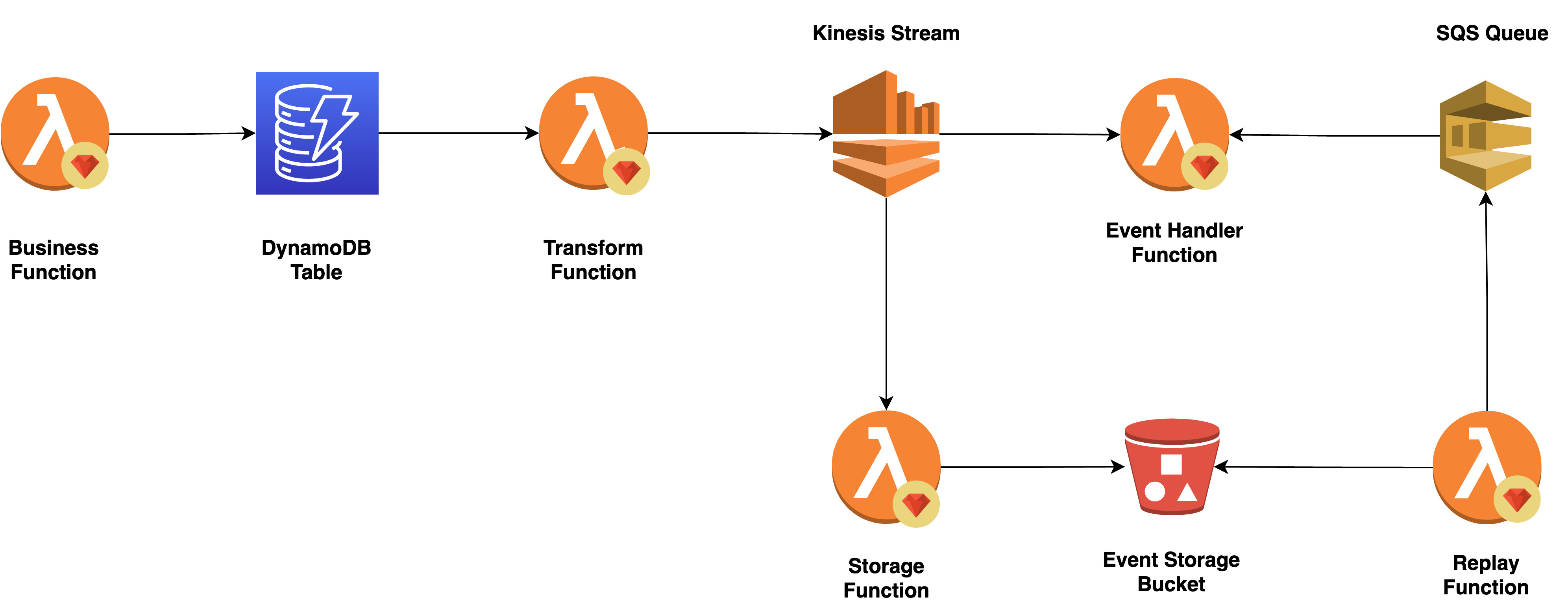
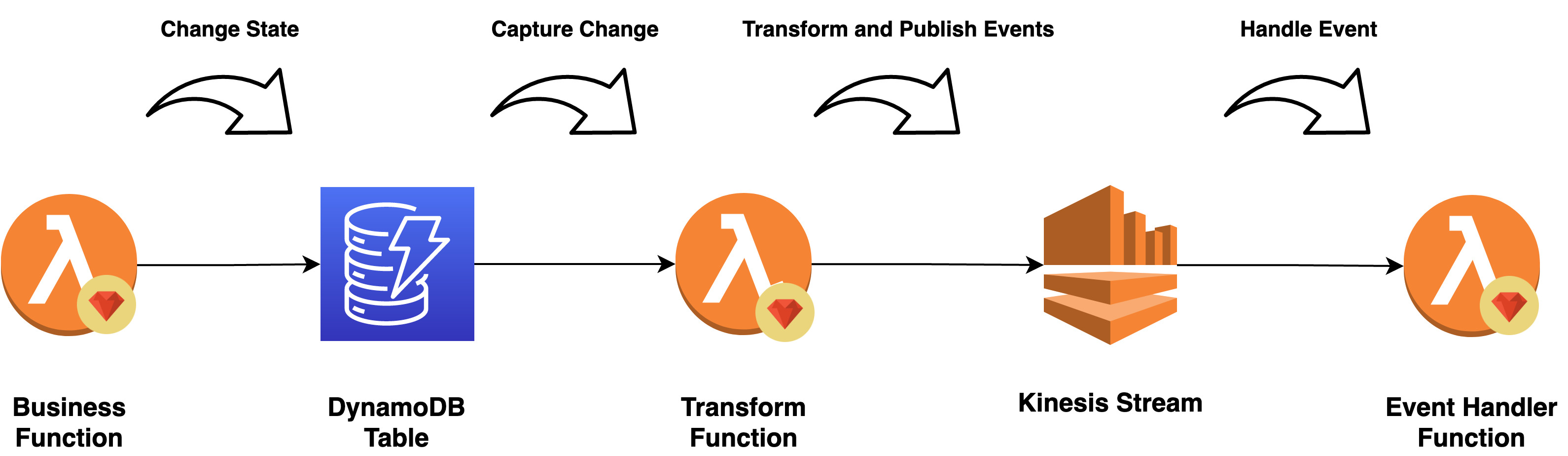
Requests will flow into our Lambdas which hosts our ShoppingCart business logic. When this happens, our application will rehydrate a Shopping Cart aggregate and execute a single business function against it.
Rehydration happens by retrieving events from a DynamoDB table and not from the Kinesis stream. In this regard, you can think of Kinesis stream as the “all-events-stream” and each DynamoDB as a stream for each “aggregate”. New events are persisted alongside old ones inside the table.
Change Data Capture is achieved using DynamoDB Streams. All events are Captured to an internal stream and handled by a Lambda to Transform them into JSON and Publish them to our Kinesis “all-event-stream”. Next, a “storage” Lambda will be used to store our published events in an S3 Bucket for long term storage and replayability.
At this point, Event Handlers have the opportunity to consume an event by subscribing to the Kinesis “all-event-stream”.
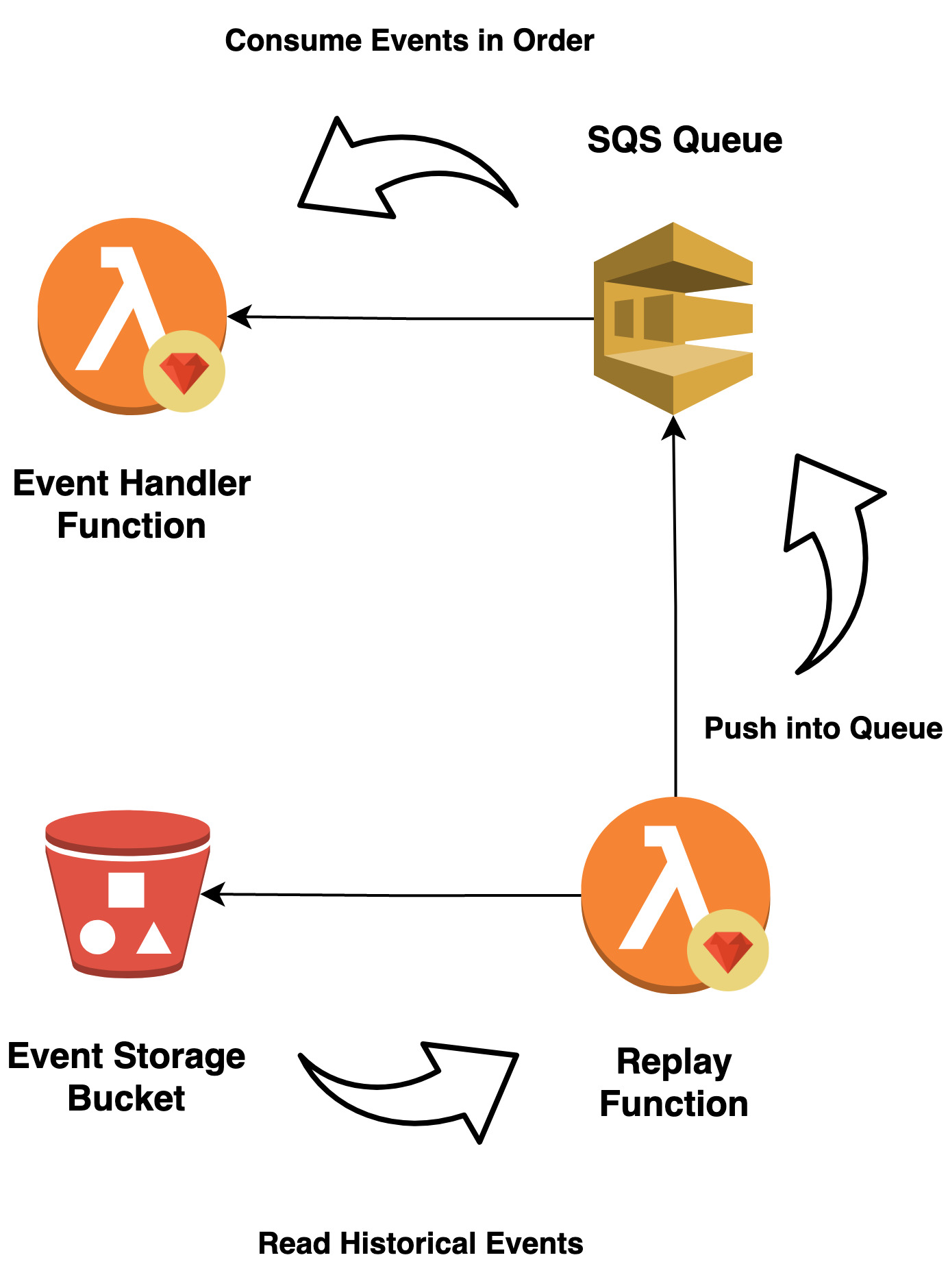
Lastly, when it suits our needs, we can replay all historical events to any Event Handler required. A replay Lambda function will read all events stored in S3 and publish them to the Event Handler SQS queue.
This means our Event Handlers require two subscriptions: Kinesis Stream for new events and an SQS queue for replayed events.
Infrastructure as Code and Terraform
We’re at the end of our first step in this series. However, it’s critical to discuss Infrastructure as Code as it will sit at the core of our implementation.
Building infrastructure by hand is a very meticulous task and often error prone due to Layer 8 mistakes. Even more so, if the same infrastructure needs to be built within multiple environments, it can become seriously time inefficient to do this by hand!
This is where Infrastructure as Code (IaC) comes into play. as Code (IaC) comes into play. With IaC, infrastructure configuration and deployment can be automated and repeatable. Additionally, it makes managing environments easier and gives you a single source of truth.
Some examples of IaC are:
- Chef, a Ruby DSL
- Ansible, a Python DSL
- CloudFormation, AWS specific, written in JSON or YAML
- Terraform, implemented in GoLang.
Be warned - not all IaC technologies are created equal! For this project we will use Terraform. In my experience, it does a fantastic job at achieving iachieving it staying out of the way of engineers. Additionally, it works across many Cloud providers and is a highly reusable skill.
An example of how powerful Terraform can be, let’s look at an example. It’s possible to boot up a PostgreSQL database in any environment with two simple steps:
First, add the following declaration to a file named database.tf (the file name does not particularly matter):
1resource "aws_db_instance" "my-psql-db" {
2 allocated_storage = 10
3 db_name = "my_postgres_db"
4 engine = "postgresql"
5 instance_class = "db.t3.micro"
6 username = "super_secure_username"
7 password = "super_secure_password"
8}
Second, execute the apply command in the directory that hosts your terraform code:
1$ terraform apply
Viola! You now have a Postgres database running in our AWS account. How wicked is that?
NOTE: In case you do try this, you can execute terraform destroy to remove the database and save yourself some money ;)
Conclusion
We’ve covered the design portion of our Event Sourcing application. We touched on the architecture and the technologies that make up its parts.
You may go back to the introduction page or directly to the next article; Aggregate Design where we start implementing our design.