
This is the fourth part in an on-going blog series about building an event sourcing system in Ruby using AWS Serverless technologies.
The persistence of values and complex objects is essential to modern applications. Applications that take tremendous care of how their objects actually pass in-and-out of memory tend to perform far better than those that don’t - especially in the face of changing and growing requirements.
This article covers how to implement aggregate persistence using the Repository pattern. It utilizes previously built DynamoDB table from our event store.
Repository Class
With our event store table ready to be used, we can turn our attention towards the Class that interfaces with it: The ShoppingCartRepo.
About the Repository Pattern
The repository pattern is a data abstraction pattern for querying and persisting objects. Its responsibility is to ensure it provides whole objects when providing them and persists all changes when storing them.
The Repository Pattern is often compared against the ActiveRecord pattern. The two key differences are:
- With the ActiveRecord pattern, persistence methods are implemented on the entites themselves. Entities understand and control persistence.
- With the Repository pattern, persistence is delegated to a second object called the repository, freeing entities from persistence responsibility. The repository must return a whole object with its relations. Whereas with ActiveRecord, related objects can be dynamically queried for after the initial data access.
So how is this pattern implemented? Well…
Impressions of How They Are Implemented
At times, the repository pattern’s literature is eclectic and difficult to understand. Much of it is opinion-based and often handed down from one generation of engineering teams to another.
Therefore, it’s imperative for us to get on the same page about what it means for us.
I quite enjoy the way Vaugn Vernon summarizes Repositores in his book, Implementing Domain Driven Design, also known as ‘The Red Book’, which I’ll paraphrase:
There are two kinds of repositories. The first acts as a collection and provides an interface for accessing entities as if they were already loaded in-memory. Changed entities are persisted by passing them to a
savemethod. The second type offers only two methods: fetch and store, which fetch and persist single changed entities.
A helpful way to look at this is, there are two types of Repository patterns:
- One that is really effective at meeting complex querying needs. This is highly suited to the Q in CQRS.
- One that is really effective at building and saving a single complex object. This is highly suited to the C in CQRS.
For accessing our aggregates, we will employ the latter definition.
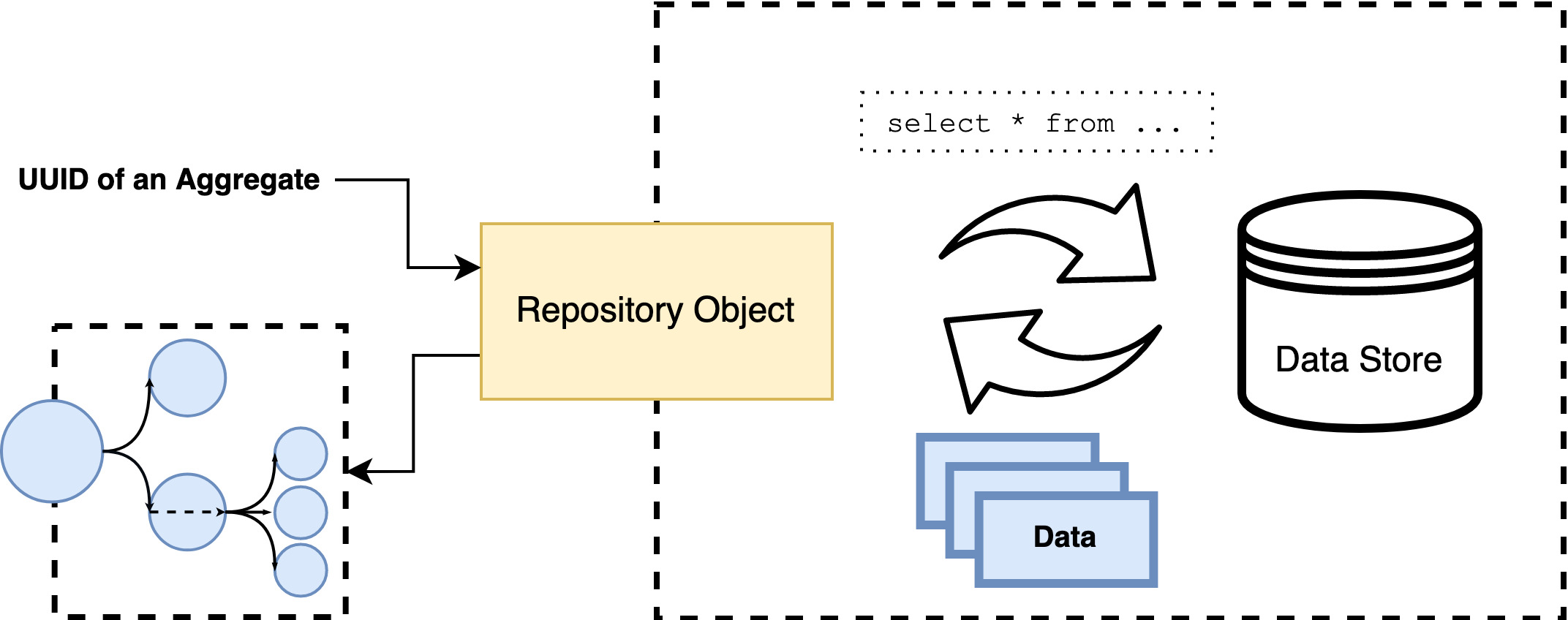
In large applications that deal with increasingly diverse read and write operations, it is common to have two sets of Repository objects that implement this pattern. Often, a collection-like repository will implement only an interface for intended queries which delegate to Query classes.
Repository Outline
Our repository will have only two methods: fetch and store, where fetch accepts a single uuid and store accepts an entire aggregate.
Additionally, our repository will require access to DynamoDB. This will be injected as a dependency.
1class ShoppingCartRepo
2 def initialize(dynamodb_client)
3 @dynamodb_client = client
4 end
5
6 def fetch(uuid)
7 # Will implement
8 end
9
10 def store(shopping_cart)
11 # Will implement
12 end
13end
Store Method
Before we can fetch we must be able to store.
The store method has three responsibilities:
- Persisting new events (changes) queued in the aggregate.
- Provide optimistic locking (prevent change collisions).
- Clearing persisted events and returning a clean aggregate, ready for further interactions.
When persisting changes, each change will be persisted as a unique record in our DynamoDB table. Record uniqueness is guaranteed by two DynamoDB table attributes:
- The AggregateUuid, which is the hash key.
- The Version, which is the range key.
Plus, Version is the attribute providing optimistic locking. We’ll see how this is achieved later.
Persistence
Our store method.
1class ShoppingCartRepo
2 # ...
3 def store(shopping_cart)
4 new_version = shopping_cart.version # Will be added below
5
6 new_events = shopping_cart.changes.map do |event|
7 new_version = new_version + 1 # New version for each event
8
9 {
10 EventUuid: SecureRandom.uuid,
11 AggregateUuid: shopping_cart.uuid,
12 Name: event.class::NAME,
13 Data: event.to_h,
14 Version: new_version
15 }
16 end
17
18 put_operations = events.map do |event|
19 {
20 put: {
21 item: event,
22 table_name: "scd-es-table",
23 condition_expression: "attribute_not_exists(#v)", # Provides optimistic locking
24 expression_attribute_names: {
25 "#v" => "Version"
26 }
27 }
28 }
29 end
30
31 @dynamodb_client.transact_write_items({transact_items: put_operations})
32
33 shopping_cart.clear_changes
34 shopping_cart.version = new_version
35 shopping_cart
36 end
37end
Firstly, we transform newly published events into a collection of hashes that will be stored as data. Part of this transformation is providing an incremented version for individual events.
The starting event number must come from the supplied aggregate. So we’ll add this functionality to the Aggregate module. As we’ll see later, the fetch method sets the aggregate version..
1module Aggregate
2 # ...
3 def version
4 @version || 0
5 end
6
7 def version=(new_version)
8 @version = new_version.to_i
9 end
10 # ...
11end
With DynamoDB, you may persist multiple changes in a transaction similar to relational databases. However, we must describe all operations and execute them in a single call.
Part of transforming events is transforming the actual event data into a structure suited to persistence. DynamoDB is a document store, so it handles Hashes just fine.
In order to accomplish this, our events must implement the to_h method.
1class CartOpened
2 attr_reader :shopping_cart_uuid
3
4 # ...
5
6 def to_h
7 { shopping_cart_uuid: @shopping_cart_uuid }
8 end
9end
10
11class ItemAdded
12 attr_reader :shopping_cart_uuid, :item_name
13
14 # ...
15
16 def to_h
17 { shopping_cart_uuid: @shopping_cart_uuid, item_name: @item_name }
18 end
19end
Finally, store executes the transaction and persists all changes as records.
Providing Optimistic Locking
In my personal opinion, this is the most integral responsibility of a repository object - to prevent data collisions.
Optimistic Locking is a kind of application level lock. Before changing a table record, an application reads the record from the database and keeps note of the version columns value.
During the data update phase, the application will abort the transaction if the version values are not the same. This prevents having to create table or records locks in the database.
Normally, in DynamodDB tables, if a record with a matching hash and range pair already exists it is overwritten entirely. With conditional_expressions, it alters this behaviour to throw an exception.
Here is a jist from above.
1{
2 # ...
3 condition_expression: "attribute_not_exists(#v)",
4 expression_attribute_names: {
5 "#v" => "Version"
6 }
7 # ...
8}
Our conditional_expression works by using a DynamoDB function called attribute_not_exists which only allows the expression to be committed if it evaluates to true. In our case, the expression allows commits to occur if the Version does not already exist.
One critical detail to remember, Version is a range field. Its value is only unique within its own range for the entitie’s hash (AggregateUuid).
A Quick Example
Consider the following table:
| AggregateUuid | Version |
|---|---|
| uuid-1 | 1 |
| uuid-1 | 2 |
| uuid-2 | 1 |
There are three events for two seperate aggregates.
An attempt to insert another event with the AggregateUuid equal to uuid-1 and Version of 2 would result in an exception because the ranged value of Version already exists.
On the otherhand, an attempt to insert another event with the AggregateUuid equal to uuid-2 and Version of 2 would be successful.
Clearing Changes
Lastly, our store method needs to clear persisted events on the Aggregate. We can achieve this by implementing a method in the Aggregate module.
Our store method is complete and our aggregates can now be stored! Congratulations!
Fetch Method
The best for last! First, let’s discuss how aggregates are initialized.
Preparing our Aggregate Module
Currently, to instantiate our ShoppingCart, we must provide a uuid.
1
2class ShoppingCart
3 include Aggregate
4
5 attr_reader :items
6
7 def initialize(uuid)
8 @items = []
9
10 enqueue(CartOpened.new(uuid))
11 end
12
13 # ...
14end
What about when we need to rehydrate an aggregate? We cannot instantiate an empty aggregate without enqueuing a “start” event - in our case, a CartOpened. There are several options.
We could move the responsibilities of building a ShoppingCart to a build method. This will instantiate the aggragate and apply the starting correct event but there are some drawbacks. We now have two methods for instantiating objects and it can be confusing which one to use, especially as more engineers join the project.
We could move the responsibility of instantiating a ShoppingCart aggregate and CartOpened event to the repository. This is where an aggregate is instantiated and the CartOpened starting event is applied. This too has some drawbacks. For one, the event which belongs to the domain model is now part of the repository! The model has very limited control over when these events become applied. No bueno!
I’m sure there are other clever ways to do this in Ruby. However, there is one pragmatic way I’ve come to enjoy: nullifying arguments.
When instantiating an aggregate, we can pass in a uuid as nil. By doing so, the aggregate decides wether to enqueue a starting event or not. The aggregate retains control of when events are published and keeps a single method for instantiating aggregates.
We’ll apply this principle to the ShoppingCart aggregate.
1class ShoppingCart
2 include Aggregate
3
4 attr_reader :items
5
6 def initialize(uuid = nil) # uuid is allowed to be nil
7 @items = []
8
9 enqueue(CartOpened.new(uuid)) unless uuid.nil? # if it's new, it's a blank object
10 end
11
12 def add_item(item_name)
13 enqueue(Events::ItemAdded.new(uuid, item_name))
14 end
15
16 on CartOpened do |event|
17 @uuid = event.shopping_cart_uuid
18 end
19
20 on ItemAdded do |event|
21 @items = @items.append(event.item_name)
22 end
23end
In a way, I find similarities to the Null-Object pattern.
Implementing fetch
The fetch method has three responsibilities:
- Query for a range of previous events using a
uuidand apply them against an aggregate. - Ensure the latest version is set.
- If no events can be found or the
uuidisnil, returnnil.
1class ShoppingCartRepo
2 def initialize(dynamodb_client)
3 @dynamodb_client = dynamodb_client
4 end
5
6 def fetch(uuid)
7 shopping_cart = ShoppingCart.new
8
9 events = fetch_aggregate_events(uuid)
10
11 return nil if events.empty?
12
13 shopping_cart.version = events.last.fetch("Version").to_i
14
15 events
16 .map { |event| build_event(event) }
17 .reject(&:nil?)
18 .each { |event| shopping_cart.apply(event) }
19
20 if shopping_cart.uuid.nil?
21 nil
22 else
23 shopping_cart
24 end
25 end
26
27 private
28
29 def fetch_aggregate_events(aggregate_uuid)
30 query_options = {
31 table_name: "scd-es-table",
32 key_condition_expression: "AggregateUuid = :aggregate_uuid",
33 expression_attribute_values: {
34 ":aggregate_uuid" => aggregate_uuid,
35 },
36 consistent_read: true
37 }
38
39 items = []
40
41 result = @dynamodb_client.query(query_options)
42
43 loop do
44 items << result.items
45
46 break unless (last_evaluated_key = result.last_evaluated_key)
47
48 result = @dynamodb_client.query(query_options.merge(exclusive_start_key: last_evaluated_key))
49 end
50
51 items.flatten
52 end
53
54 def build_event(raw_event)
55 name = raw_event.fetch('Name')
56 data = raw_event.fetch('Data')
57
58 case name
59 when "CartOpened"
60 Events::CartOpened.new(data.fetch("shopping_cart_uuid"))
61 when "ItemAdded"
62 Events::ItemAdded.new(data.fetch("shopping_cart_uuid"), data.fetch("item_name"))
63 when "CartClosed"
64 Events::CartClosed.new(data.fetch("shopping_cart_uuid"))
65 else
66 nil
67 end
68 end
69
70 # ...
71end
Our new fetch starts be instantiating a blank ShoppingCart by passing in nil as the uuid. This means the aggregate has not applied a CartOpened event. Afterwords, events are queried from DynamoDB using a the key_condition_expression.
In order to ensure we are querying all available records, we must paginate over the evaluation set.
If it cannot find any events, it returns nil rather than an aggregate. Otherwise, it loops over each record, first initializing an event and then applying it against the aggregate.
At the end, if the uuid of the aggregate is not nil, the rehdrated ShoppingCart is returned. Otherwise, nil.
When would uuid be nil?
If our query returns a collection of events and our starting event always provides a uuid, when would it be nil?
One of the core aspects of event sourcing is that events are never deleted nor altered. The event store is append-only and the events themselves are immutable! This begs the question, how are aggregates “deleted”?
By another event of course! In eventually consistent systems, an event that signifies the end of an object’s life is called a Tombstone. The motivation section in the Wikipedia entry describes this as (emphasis mine),
If information is deleted in an eventually-consistent distributed data store, the “eventual” part of the eventual consistency causes the information to ooze through the node structure, where some nodes may be unavailable at time of deletion. But a feature of eventual consistency causes a problem in case of deletion, as a node that was unavailable at that time will try to “update” the other nodes that no longer have the deleted entry, assuming that they have missed an insert of information. Therefore, instead of deleting the information, the distributed data store creates a (usually temporary) tombstone record, which is not returned in response to requests.
When our aggregate should be deleted, another event is enqueued which sets the uuid to nil effectively deleting it. Eventually, downstream consumers will receive this event and decide what a tombstone means for their domain.
Consider the diagram below.
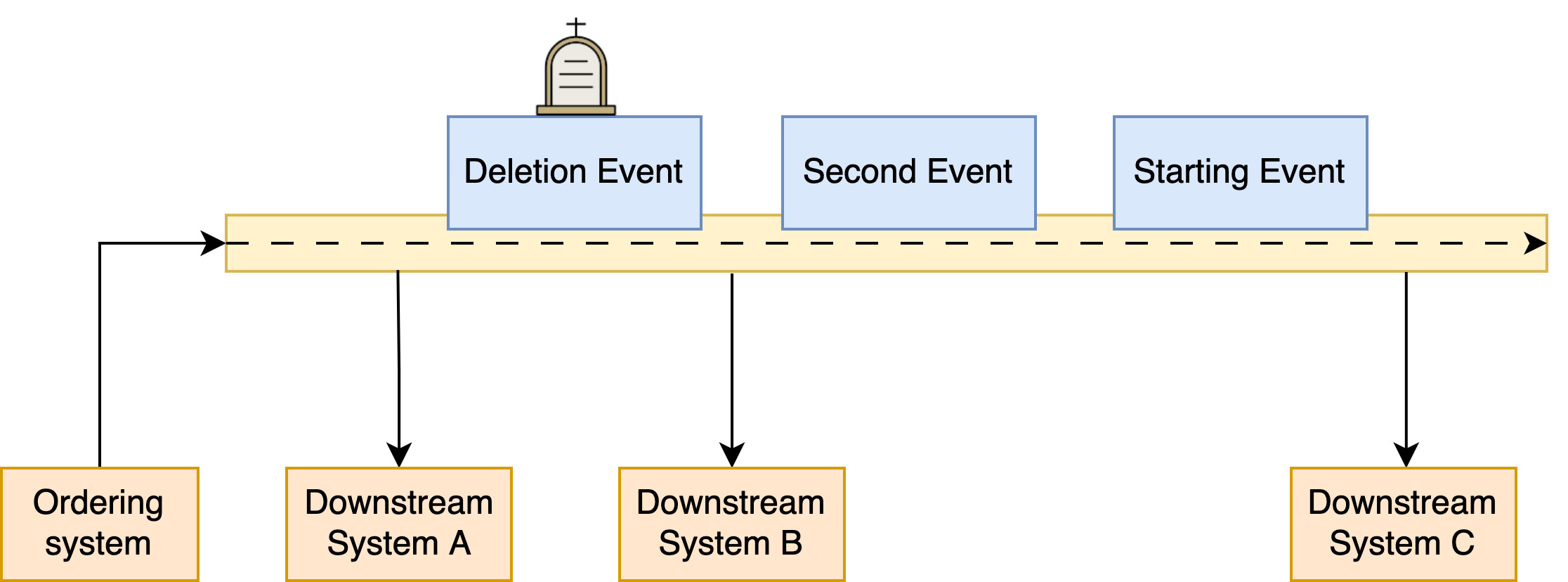
In this application, there exists an Ordering System which produces events into a stream. In this particular frame in time, a series of events have occurred which signal the creation of an object through a starting event and the deletion of an object through a tombstone event.
The Ordering System is immediately consistent, so it knows that data has been deleted. Downstream System A has already processed all events that have occurred in the event stream and knows that data has been deleted as well.
However at the same time, Downstream System B is about to discover that data has been deleted from the Ordering System. While Downstream System C hasn’t even known the data existed in the first place.
In our ShoppingCart, we can define this behaviour with a CartClosed event.
1class ShoppingCart
2 # ...
3
4 def close
5 enqueue(CartClosed.new(uuid))
6 end
7
8 on CartClosed do |event|
9 @uuid = nil
10 end
11
12 # ...
13end
Whenever a closed (deleted) ShoppingCart is rehydrated, the final event will be CartClosed. This will prevent the aggregate from being returned.
Small Cleanup
Our repository looks good but it’s breaking a few SOLID rules. If we carefully read through its code, two things stand out:
- There is a wide array of responsibilities in a single class.
- Aside from the events, there is hardly anything about this implementation that seems
ShoppingCartspecific.
We can make this far better.
Refactoring
We’ll refactor our ShoppingCartRepo to abstract persistence behaviours into a base class. Our goal is to accomplish two objectives:
- All aggregate repositories inherit from the same base class and behave the same way.
- To create a code that is easier to maintain, it is desirable to separate concerns.
Martin Fowler’s Refactoring describes a comprehensive set of refactoring approaches. We’ll apply a few here.
EventBuilder Class
Our repository does not need to understand how events are built. It may delegate this to a second class. Using the Extract Class refactoring, we’ll extract this behaviour to its own class and inject it as a dependency.
1module Events
2 class Builder
3 def build(name, data)
4 case name
5 when "CartOpened"
6 CartOpened.new(data.fetch("shopping_cart_uuid"))
7 when "ItemAdded"
8 ItemAdded.new(data.fetch("shopping_cart_uuid"), data.fetch("item_name"))
9 else
10 nil
11 end
12 end
13 end
14end
Injecting the new class as a dependency and replacing the existing build implementation with a call to the event_builder object.
1class ShoppingCartRepo
2 def initialize(dynamodb_client, event_builder)
3 @dynamodb_client = client
4 @event_builder = event_builder # New event builder class
5 end
6
7 # ... fetch and store
8
9 def build_event(raw_event)
10 event_builder_module.build(raw_event.fetch('Name'), raw_event.fetch('Data'))
11 end
12end
Tailored DynamoDB Client
The repository is responsible for both accessing the underlying persistence technology and building an aggregate. Let’s separate this.
First, we’ll use Extract Function refactoring to move data persistence from store into its own method.
1class ShoppingCartRepo
2 # ...
3
4 def store(shopping_cart)
5 new_version = shopping_cart.version # Will be added below
6
7 new_events = shopping_cart.changes.map do |event|
8 new_version = new_version + 1 # New version for each event
9
10 {
11 EventUuid: SecureRandom.uuid,
12 AggregateUuid: shopping_cart.uuid,
13 Name: event.class::NAME,
14 Data: event.to_h,
15 Version: new_version
16 }
17 end
18
19 insert_aggregate_events!(new_events) # Call new method
20
21 shopping_cart.clear_changes
22 shopping_cart.version = new_version
23 shopping_cart
24 end
25
26 private
27
28 def insert_aggregate_events!(events)
29 put_operations = events.map do |event|
30 {
31 put: {
32 item: event,
33 table_name: "scd-es-table",
34 condition_expression: "attribute_not_exists(#v)",
35 expression_attribute_names: {
36 "#v" => "Version"
37 }
38 }
39 }
40 end
41
42 @dynamodb_client.transact_write_items({transact_items: put_operations})
43
44 nil
45 end
46end
Next, we’ll use Extract Class refactoring once again to move data access into its own class. Luckily for us, querying events is already isolated into its own method.
1class EsDynamoTableClient
2 def initialize(dynamodb_client, table_name)
3 @dynamodb_client = dynamodb_client
4 @table_name = table_name
5 end
6
7 def fetch_aggregate_events(aggregate_uuid)
8 query_options = {
9 table_name: @table_name,
10 key_condition_expression: "AggregateUuid = :aggregate_uuid",
11 expression_attribute_values: {
12 ":aggregate_uuid" => aggregate_uuid,
13 },
14 consistent_read: true
15 }
16
17 items = []
18
19 result = @dynamodb_client.query(query_options)
20
21 loop do
22 items << result.items
23
24 break unless (last_evaluated_key = result.last_evaluated_key)
25
26 result = @dynamodb_client.query(query_options.merge(exclusive_start_key: last_evaluated_key))
27 end
28
29 items.flatten
30 end
31
32 def insert_aggregate_events!(events)
33 put_operations = events.map do |event|
34 {
35 put: {
36 item: event,
37 table_name: @table_name,
38 condition_expression: "attribute_not_exists(#v)",
39 expression_attribute_names: {
40 "#v" => "Version"
41 }
42 }
43 }
44 end
45
46 @dynamodb_client.transact_write_items({transact_items: put_operations})
47
48 nil
49 end
50end
Now, our ShoppingCartRepo looks much simpler.
1class ShoppingCartRepo
2 def initialize(dynamodb_client, event_builder)
3 @dynamodb_client = dynamodb_client
4 @event_builder = event_builder
5 end
6
7 def fetch(uuid)
8 shopping_cart = ShoppingCart.new
9
10 events = @dynamodb_client.fetch_aggregate_events(uuid) # We call the new class explicitly
11
12 return nil if events.empty?
13
14 shopping_cart.version = events.last.fetch("Version").to_i
15
16 events
17 .map { |event| build_event(event) }
18 .reject(&:nil?)
19 .each { |event| shopping_cart.apply(event) }
20
21 if shopping_cart.uuid.nil?
22 nil
23 else
24 shopping_cart
25 end
26 end
27
28 def store(shopping_cart)
29 new_version = shopping_cart.version
30
31 new_events = shopping_cart.changes.map do |event|
32 new_version = new_version + 1
33
34 {
35 EventUuid: SecureRandom.uuid,
36 AggregateUuid: shopping_cart.uuid,
37 Name: event.class::NAME,
38 Data: event.to_h,
39 Version: new_version
40 }
41 end
42
43 @dynamodb_client.insert_aggregate_events!(new_events) # We call the new class explicitly
44
45 shopping_cart.clear_changes
46 shopping_cart.version = new_version
47 shopping_cart
48 end
49
50 # ...
51end
DynamoDBRepo Parent Class
Future aggregate repos will benefit from an existing class which implements aggregate rehydration and persistence behaviours.
First, we’ll define our parent class and inherit it from the ShoppingCartRepo class.
1class DynamoDBRepo
2 def initialize(dynamodb_client)
3 @dynamodb_client = dynamodb_client
4 end
5end
6
7class ShoppingCartRepo < DynamoDBRepo
8 # ...
9end
Then, using the Pull Up Method refactoring, we’ll move fetch and store into the parent class.
1class DynamoDBRepo
2 def initialize(dynamodb_client, event_builder)
3 @dynamodb_client = dynamodb_client
4 @event_builder = event_builder
5 end
6
7 def fetch(uuid)
8 shopping_cart = ShoppingCart.new
9
10 events = @dynamodb_client.fetch_aggregate_events(uuid) # We call the new class explicitly
11
12 return nil if events.empty?
13
14 shopping_cart.version = events.last.fetch("Version").to_i
15
16 events
17 .map { |event| build_event(event) }
18 .reject(&:nil?)
19 .each { |event| shopping_cart.apply(event) }
20
21 if shopping_cart.uuid.nil?
22 nil
23 else
24 shopping_cart
25 end
26 end
27
28 def store(shopping_cart)
29 new_version = shopping_cart.version
30
31 new_events = shopping_cart.changes.map do |event|
32 new_version = new_version + 1
33
34 {
35 EventUuid: SecureRandom.uuid,
36 AggregateUuid: shopping_cart.uuid,
37 Name: event.class::NAME,
38 Data: event.to_h,
39 Version: new_version
40 }
41 end
42 end
43end
44
45class ShoppingCartRepo < DynamoDBRepo
46 # Now an EmptyClass
47end
There is one last alteration to make. DynamoDBRepo class still references the ShoppingCart aggregate.
We can fix this with meta-programming by making the ShoppingCart class tell its parent what sort of aggregate it needs.
1class DynamoDBRepo
2 class AggregateClassUndefined < StandardError
3 def message
4 "Aggregate class is not defined"
5 end
6 end
7
8 @aggregate_class = nil
9
10 def initialize(dynamodb_client, event_builder)
11 @dynamodb_client = dynamodb_client
12 @event_builder = event_builder
13
14 raise AggregateClassUndefined if aggregate_class.nil?
15 end
16
17 def self.aggregate(aggregate_class)
18 @aggregate_class = aggregate_class
19 end
20
21 def self.aggregate_class
22 @aggregate_class
23 end
24
25 # ...
26
27 private
28
29 def aggregate_class
30 self.class.aggregate_class
31 end
32
33 def event_builder_module
34 self.class.event_builder_module
35 end
36end
Our repository can now be configured by specifying that it should be used to store and build aggregates for ShoppingCart.
Personally, I believe the same behaviour should be used for the EventBuilder class as well.
By using the Pull Down Field refactoring, we can achieve the same result. I’ll omit the details from here, as we’ll conclude with a breif overview shortly.
1class ShoppingCartRepo < DynamoDBRepo
2 aggregate ShoppingCart
3 event_builder Events::Builder
4end
Refactoring Conclusion
This type of refactoring makes small adjustments that improve a problematic area of code over time. It favors small consistent wins over large - and potentially dangerous - restructurings.
Quite a few changes were presented with omitted code blocks. For a full capture of the ShoppingCartRepo, DynamoDBRepo, and EsDynamoTableClient classes, you may view them on this GitHub Gist.
Test Run
Let’s take our repository for a spin.
1require 'aws-sdk-dynamodb'
2
3# DynamoDB Client
4dynamo_db_client = EsDynamoTableClient.new(Aws::DynamoDB::Client.new, "scd-es-table")
5
6# ShoppingCartRepo
7shopping_cart_repo = ShoppingCartRepo.new(dynamo_db_client)
8
9shopping_cart = ShoppingCart.new("test-uuid")
10
11shopping_cart.add_item("apiercey.github.io subscription")
12
13# There should now be two events in @changes
14
15puts shopping_cart.inspect
16
17shopping_cart_repo.store(shopping_cart)
Taking a peek into our DynamoDB table, we see the record there, with the set of changes as events.
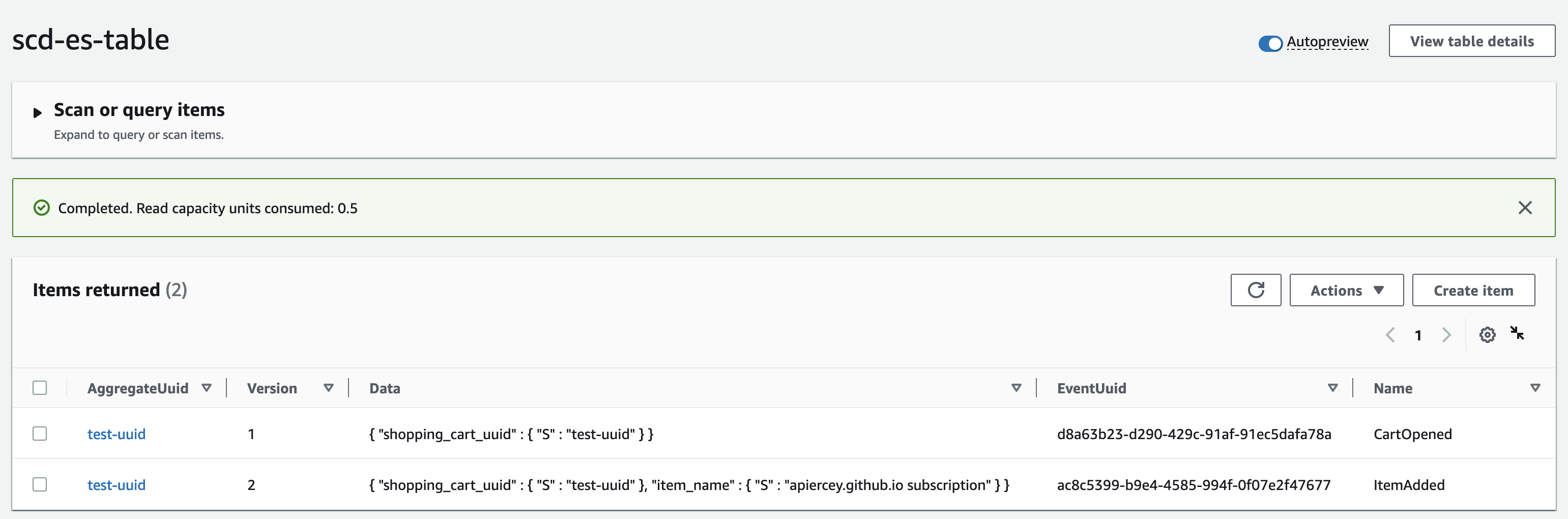
We can fetch the same shopping cart and inspect its state.
1rehydrated_shopping_cart = shopping_cart_repo.fetch("test-uuid")
2
3rehydrated_shopping_cart.inspect
inspecting the object should show us a complete ShoppingCart with a uuid and an item.

Conclusion
We’ve brought our aggregates full circle and can now create and rehydrate them for future use. We’ve done this by leveraging our DynamoDB table and the repository pattern.
Most importantly, we discovered how change collisions can be prevented using the Optimistic Locking strategy and why it’s so crucial to do so.
Additionally, we saw how we could refactor complex classes to gradually become more simple.
The full code for part three of our event sourcing application can be found here: https://github.com/APiercey/aws-serverless-event-sourcing/tree/part-four-aggregate-persistence
Next, we will take the first step into building event handlers for these events using Change Data Capture. We’ll accomplish this using DynamoDB Streams, Lambda, and Kinesis!