
This is the second part in an on-going blog series about building an event sourcing system in Ruby using AWS Serverless technologies.
Aggregate design is at the center of how event sourcing systems operate. They encapsulate our events into a greater meaning than the sum of its parts.
We will implement our ShoppingCart aggregate, the events it publishes, and how these events are applied to alter its state. This will be the foundation of our system.
Aggregate Crash Course
Let’s briefly discuss what they are and which problem they solve.
Aggregates are groups of objects that enforce business constraints with one acting as the root object. The root object acts as the spokesobject for the others and nothing can access the internal objects without traversing the root object first. In DDD nomenclature, these objects are composed of Entities and Value objects.
This means things outside of the aggregate cannot reference an internal object directly - it must always ask the root object for access to its internal objects.
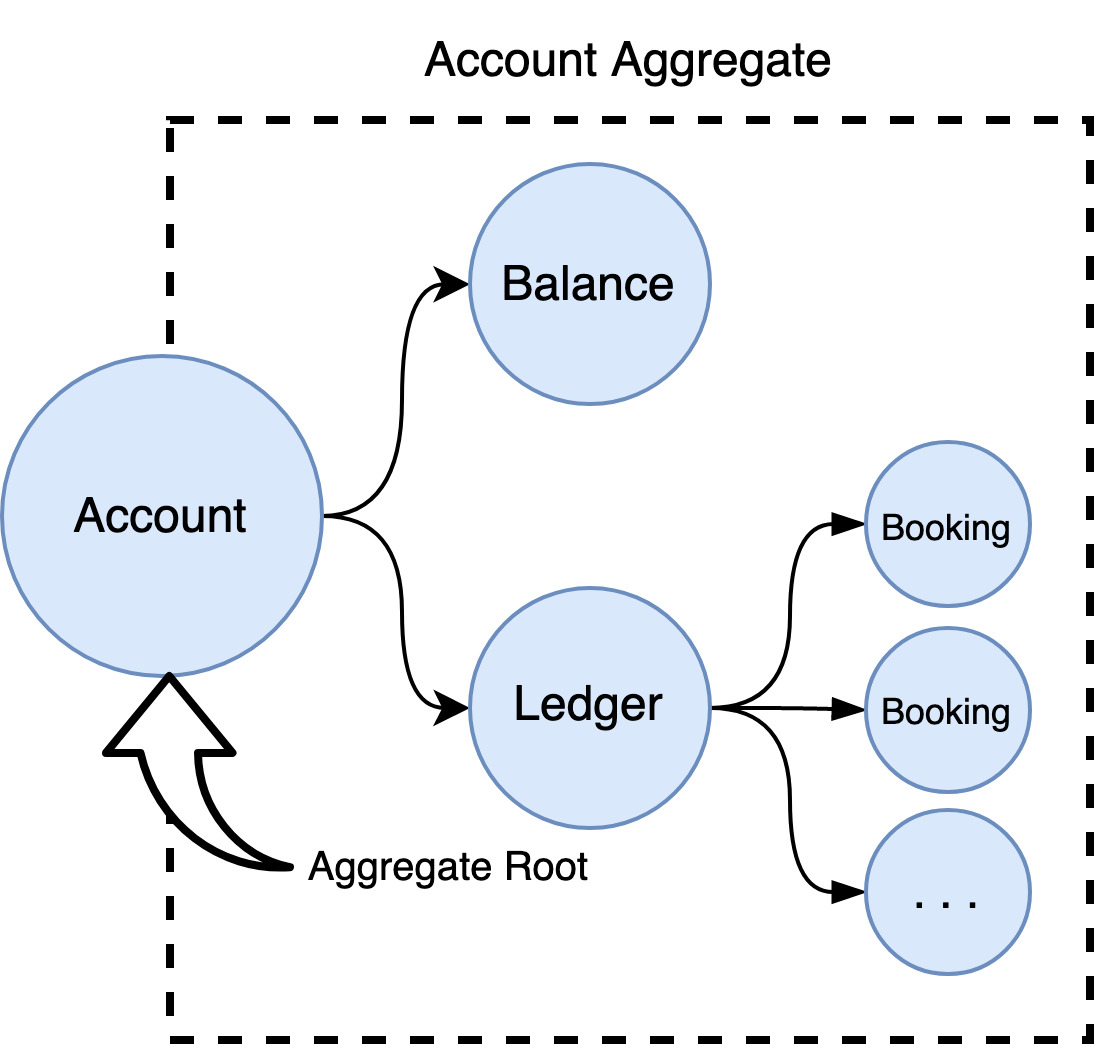
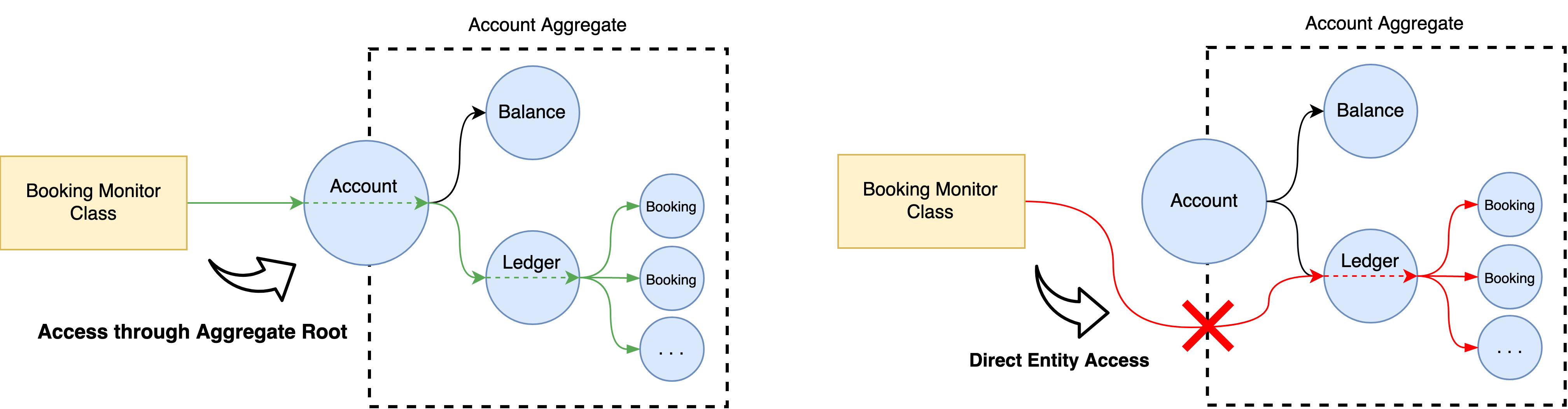
For example, consider a ledger system that carries Accounts and Bookings. The diagram below shows a Booking Monitoring Class that needs access to an account’s bookings. On the left, the Booking Monitoring Class gains access to these bookings by requesting them through the Aggregate Root entity’s public interface. While on the right, the same class incorrectly gains access by circumventing the Aggregate Root and accessing bookings directly.
In the example on the right, the aggregate provides weak protection against direct access.
This has several fantastic benefits.
First, meaningful relationships between objects in your domain are formed, instead of ones that are logically derived, making your domain model more expressive.
Second, because external entities must always interact through the aggregate root, system constraints must always be located within an aggregate. This gives the application’s critical rules a singular home and protects multiple (and often different) implementations of a rule throughout an application.
Lastly, an entire aggregate is treated as a object collection boundary. These objects live together and their state is singular, persisted and rehydrated from the data store as a single cohesive unit. This provides assurance the state is fully loaded and ready.
1account = AccountRepository.fetch(account_identifier)
2=> #<Account @uuid="..." @bookings=[#<Booking ...>, ...]>
3
4# account traverses through the ledger object
5account.bookings
6=> [#<Booking ...>, ...]
The account is the gatekeeper for all business logic. If we need to execute logic against a booking, we must go through the account:
Our Account aggregate enforces one additional rule; a booking cannot exist without being associated with an account. As this is intentional, we must neglect to create the means of fetching bookings into memory.
If you have further interest in aggregate design, I highly recommend the following articles:
- https://medium.com/ssense-tech/ddd-beyond-the-basics-mastering-aggregate-design-26591e218c8c
- https://martinfowler.com/bliki/DDD_Aggregate.html
Aggregates in Ruby
Like other architectures born from circles practicing Domain-Driven Design, event sourcing focuses on modeling software to match a domain by taking critical concepts given to engineers by domain experts.
It achieves this by removing the burden of model objects aware of data persistence and elevating facts into events.
Often, the flow of executing business logic in event sourcing looks like this:
An aggregate is firstly retrieved from its repository class. Next, a method is executed to carry out a portion of business logic, and in doing so, publishes an event. Whenever an event is published, the aggregate immediately applies it against itself, changing its own state.
Finally, the aggregate is persisted using its repository class. Published events are pushed to an event stream.
This means that:
- Methods for executing business logic are responsible for enforcing the rules (E.g. Account balance cannot go below zero!)
- For every action that modifies an aggregate, there is an event.
- Newly published events to an aggregate are stored in memory, waiting to be persisted.
- Aggregates will publish many events over their lifetime.
Aggregate Design: Defining a ShoppingCart
Our shopping cart will be simple: You can open a shopping cart and add items to it. We’ll start with a tiny class definition.
Now, we’re ready to explore publishing our first event.
To create an aggregate, it needs two things:
- An identifier, ussually a UUID
- An event which signifies the starting event of that aggregate. In the CRUD world, this is the creation event.
Aggregate Design: Events
Events themselves are simple. They are static structures that describe facts that have happened. They follow only a few rules:
They are immutable.
They are named in the past tense.
They describe a meaningful concept in the domain.
Let’s define our first event.
1class CartOpened
2 attr_reader :shopping_cart_uuid
3
4 def initialize(shopping_cart_uuid)
5 @shopping_cart_uuid = shopping_cart_uuid
6 end
7end
Simple and neat. When a CartOpened object is instantiated, its members cannot be altered. Additionally, its name is in the past tense and describes a core behaviour of our system.
Aggregate Design: Publishing Events
Let’s implement just enough of our first aggregate to publish our event.
1module Aggregate
2 def self.included(base)
3 base.class_eval do
4 attr_reader :uuid
5 end
6 end
7
8 def changes
9 @changes ||= []
10 end
11
12 private
13
14 def enqueue(event)
15 changes.append(event)
16
17 self
18 end
19end
Our aggregate module will host the abstract behaviour of all aggregates. It’s responsible for managing changes as events and the aggregate uuid.
Whenever an event is queued to be published using the enqueue method, it stores that event as a change. We will see how these changes can be applied and published later.
1class ShoppingCart
2 include Aggregate
3
4 attr_reader :items
5
6 def initialize(uuid)
7 @items = []
8
9 enqueue(CartOpened.new(uuid))
10 end
11end
When our ShoppingCart is instantiated, it will generate a CartOpened event and queue this change to be published.
1ShoppingCart.new("test-uuid")
2=> #<ShoppingCart:0x0000000155b7cd60 @items=[], @changes=[#<CartOpened:0x0000000155b7cd10 @shopping_cart_uuid="test-uuid">]>
We can see a change has been queued, waiting to be applied. We are now ready to move forward with the right foundation.
Aggregate Design: Applying Events
Our ShoppingCart aggregate understands events and can queue them, but lacks the means to alter its own state. As an example from the step above, it has no uuid. Let’s expand our aggregate module to start applying events.
1module Aggregate
2 def self.included(base)
3 base.class_eval do
4 attr_reader :uuid
5
6 def self.on(event_class, &block)
7 define_method "apply_#{event_class::NAME}", &block
8 end
9 end
10 end
11
12 def changes
13 @changes ||= []
14 end
15
16 def apply(event)
17 self.send("apply_#{event.class::NAME}", event)
18
19 self
20 end
21
22 private
23
24 def enqueue(event)
25 apply(event)
26 changes.append(event)
27
28 self
29 end
30end
Now we must define how these events are applied to our ShoppingCart.
1class ShoppingCart
2 include Aggregate
3
4 attr_reader :items
5
6 def initialize(uuid = nil)
7 @items = []
8
9 enqueue(CartOpened.new(uuid)) unless uuid.nil?
10 end
11
12 on CartOpened do |event|
13 @uuid = event.shopping_cart_uuid
14 end
15end
There is a fair bit of meta-programming happening here, so let’s explore what is happening under the hood.
1module Aggregate
2 # ...
3 def self.included(base) # This will execute whenever the module is included
4 base.class_eval do
5 attr_reader :uuid
6
7 def self.on(event_class, &block) # This will become a class method for our aggregate
8 define_method "apply_#{event_class::NAME}", &block
9 end
10 end
11 end
12 # ...
13end
When the Aggregate module is included into a class, Ruby will execute the included method at run time, passing in the base class. This method accomplishes two things:
First, it ensures there is an instance member named uuid and it is only readable.
Second, it defines a new class method named on which accepts two arguments, an event class object and a block.
When the on method is called, it is responsible for defining a dynamic method at run time that accepts an event class and a block. When this dynamic method is called, it executes the supplied block. We will see how this works below.
1module Aggregate
2 # ...
3 def apply(event)
4 self.send("apply_#{event.class::NAME}", event)
5
6 self
7 end
8
9 private
10
11 def enqueue(event)
12 apply(event)
13 changes.append(event)
14
15 self
16 end
17 # ...
18end
We’ve added a new instance method named apply. It is responsible for calling the correct dynamic method, passing the event object as an argument.
Additionally, the apply method is now the first method called when applying, finally bringing the aggregate to the state it expects to be in.
However, this magic needs a bit of help. It needs to understand event name in order to create the dynamic apply methods. This can be achieved in a few ways in Ruby. We’ll be simple and add a class constant called NAME to our events:
You may derive this from the class name as well.
Lastly, we can create the apply method that is called when an event is applied by using the on method.
1class ShoppingCart
2 # ...
3 on CartOpened do |event|
4 @uuid = event.shopping_cart_uuid
5 end
6 # ...
7end
With our aggregates applying events, we are finally we are able to see the result.
1ShoppingCart.new("test-uuid")
2=> #<ShoppingCart:0x0000000135a8ac10 @items=[], @uuid="test-uuid", @changes=[#<CartOpened:0x0000000135a8ab70 @shopping_cart_uuid="test-uuid">]>
We can clearly see that the aggregate applies events correctly, as it has the correct uuid.
Aggregate Design: CQRS Intermission
Quite often, event sourcing is used in conjunction with Command-Query-Responsibility-Segregation (CQRS) as they represent a natural fit.
CQRS gives us clear seperation between writing data and reading data with Commands executing a set of business functions and Queries retreiving information.
Event sourcing provides event streams in which a specialized set of event handlers called Read Projections subscribe to.
Read Projections holds the responsibility of understanding events in the domain and transforming them into something readable. Often this is building up data in an SQL datasbase. However, the primary benefit is that it is possible to run as many Read Projections as you require.
Often, this is used to meet different querying needs. For example, you may have two Read Projections: one for inserting data into an SQL database for querying on the read side of the application and another for inserting into a CSV file used in reporting.
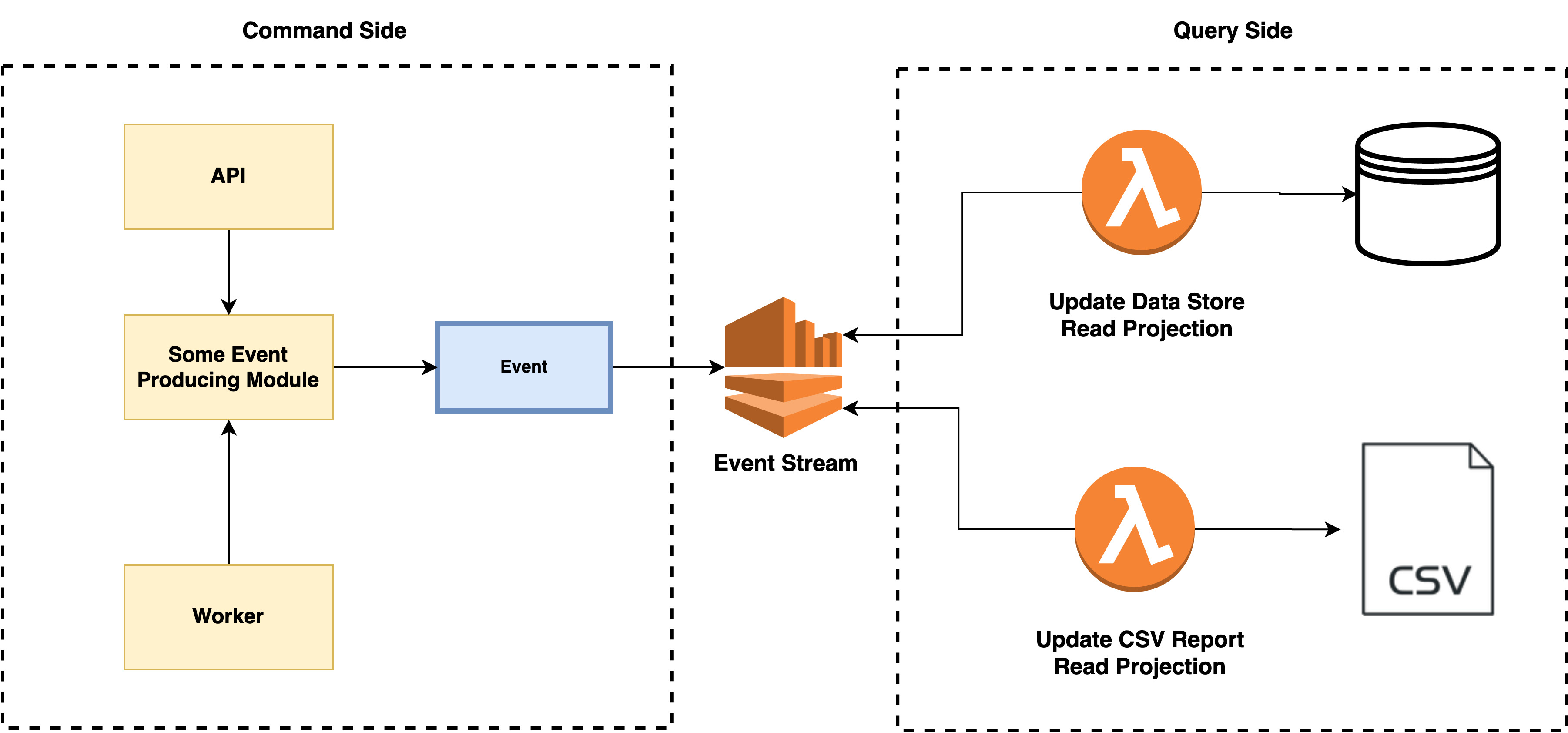
By elevating the read requirements out of objects used for enforcing and executing our business logic, we gain a write model free of this extrenuous burdon.
Commands are an effective way of expressing what your domain is designed to achieve and which business rules are enforced when they are executed. They are often implemented as distinct objects executed in an aggregate. For example, given this command exists:
1class CloseCartCommand
2 attr_reader :shopping_cart_uuid
3
4 def initialize(shopping_cart_uuid)
5 @shopping_cart_uuid = shopping_cart_uuid
6 end
7end
This could be executed using an aggregate. In doing so, an event would be published and downstream event handlers (including Read Projections) would have a chance to react.
1class CloseCartCommandHandler
2
3 # Our repo is initialized externally
4 def initialize(shopping_cart_repo)
5 @shopping_cart_repo = shopping_cart_repo
6 end
7
8 def handle(command)
9 shopping_cart = @shopping_cart_repo.fetch(command.shopping_cart_uuid)
10
11 # An event is published but not persisted
12 shopping_cart.execute(command)
13
14 # An event is persisted and pushed into the event stream
15 @shopping_cart_repo.store(shopping_cart)
16 end
17end
Aggregate Design: Command Methods
Another way Commands can be implemented, is by expressing the command as a method on an aggregate instead of a distinct object. These are called command methods.
The penalty in doing so, is we lose one degree of expressivness in our model. However, it becomes simpler.
We will use this style for our commands as our focus is on event sourcing rather than Command objects. You may want to adopt a fuller Command object in your own system if the business rules become complex.
Let’s add a command method to add items to our cart. We will start by defining a new event.
1class ItemAdded
2 NAME = "ItemAdded"
3 attr_reader :shopping_cart_uuid, :item_name
4
5 def initialize(shopping_cart_uuid, item_name)
6 @shopping_cart_uuid = shopping_cart_uuid
7 @item_name = item_name
8 end
9end
Now the command method and apply handler.
1class ShoppingCart
2 include Aggregate
3
4 attr_reader :items
5
6 # ...
7
8 def add_item(item_name)
9 enqueue(ItemAdded.new(uuid, item_name))
10 end
11
12 # ...
13
14 on ItemAdded do |event|
15 @items.append(event.item_name)
16 end
17end
The newly command method is named add_item. When it is executed against our ShoppingCart aggregate, it enqueues an ItemAdded event to be published. Under the hood, this event is applied by dynamically looking up the correct apply handler.
The apply handler will append the item to the aggregate’s list of items.
Aggregate Design: Enforcing Business Constraints
CQRS is beyond the scope of this series. However, is helps to understand the role it plays when designing our aggregates as CQRS promotes really healthy object design in complex software.
One of the critical goals of CQRS is to provide a clear understanding of where a business constraint is and having it enforced in a single location in the code.
Attempting to execute a command should always result in raising an error if the constraint is broken. This is a critical difference between other architectures such as MVC, where invalid state is allowed in our objects often accompanied by a list of errors.
At its root, event sourcing is specifically about the persistence and rehydration of our aggregates by using a collection of events. How its events are created is only an adjunct to these mechanisms.
Enforcing business constraints happens in our command methods and is straightforward.
1class ItemAlreadyAdded < StandardError
2 def initialize(uuid:, item_name:)
3 @msg = "#{item_name} has already been added to cart #{uuid}!"
4 end
5end
1class ShoppingCart
2 # ...
3 def add_item(item_name)
4 fail ItemAlreadyAdded, uuid: uuid, item_name: item_name if @items.contains?(item_name)
5
6 enqueue(ItemAdded.new(uuid, item_name))
7 end
8 # ...
9end
If an item is already added, raise an ItemAlreadyAdded error.
The idea behind this is the ability to Fail Fast. Any input which puts the system into an invalid state must fail “immediately and visibly”.
Conclusion
We’ve taken a crash course in what aggregates are and dived deep into their design for event sourcing systems. We can see how changes are executed against our aggregates with events, and where and how constraints are enforced.
Finally, we touched on why event sourcing so often goes hand-in-hand with CQRS.
You may go back to the introduction page or directly to the next article; The Event Store and DynamoDB where we introduce the event store in real detail and it’s first component.